由MESI协议看内存屏障
本文主要内容来自于:Memory Barriers: a Hardware View for Software Hackers
现代的CPU比内存系统快很多,2006年的cpu可以在一纳秒之内执行10条指令,但是需要多个十纳秒去从内存读取一个数据,这里面产生了至少两个数量级的速度差距。在这样的问题下,cpu cache应运而生。
cache处于cpu与内存之间,读写速度比内存快很多,但也比较昂贵.
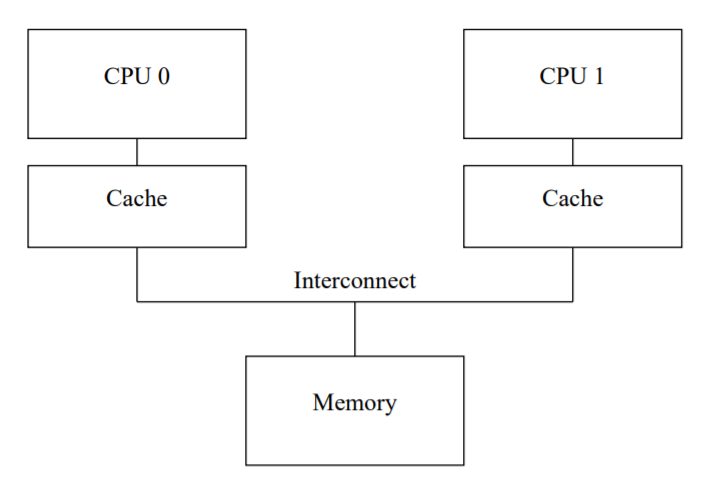
如果在多cpu的情况下,数据的读写会变得异常复杂。我们在进行读写cache的时候,不能简单地读写,因为如果只修改本地cpu的cache,而不处理其他cpu上的同一个数据,那么就会造成一份数据多个不同副本,这就是数据冲突。
我们用的最多的缓存一致性协议是MESI,四个字母分别表示modified, exclusive, shared, invalid,这是cache line的四种状态,
| 状态 | 描述 | 监听任务 |
|---|---|---|
| Modified | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在在于本Cache中 | 缓存行必须时刻监听所有试图读该缓存行在主存的操作,这种操作必须再缓存将该缓存行写回主存并将状态变成S状态之前被延迟执行 |
| Exclusive 独享、互斥 | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中 | 缓存行也必须监听其他缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S状态 |
| Shared 共享 | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中 | 缓存行也必须监听其他缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效 |
| Invalid 无效 | 该Cache line无效 | 无 |
多个cpu需要进行通信来保证缓存一致性,如果cpu共享一条总线,那么以下几种指令可以满足一致性:
Read:read消息会带上cache line的物理内存地址向其他cpu获取数据
Read Response:如果其他cpu有这个cache line,并且处于modified,那么该cpu必须返回该消息,因为其他cpu的cache line和主存都没有最新的数据
Invalidate:invalidate消息会带上cache line的物理内存地址,来让其他cache把相应的数据从cache line里去除掉
Invalidate Acknowledge:如果一个cpu收到Invalidate消息,那么它必须在删除数据之后返回该消息
Read Invalidate:该消息是Read和Invalidate的组合,所以它需要一个Read Response和多个Invalidate Acknowledge
Writeback:modified状态的cache line写到主存,可以用来腾出空间给其他数据
状态转移如下图所示:
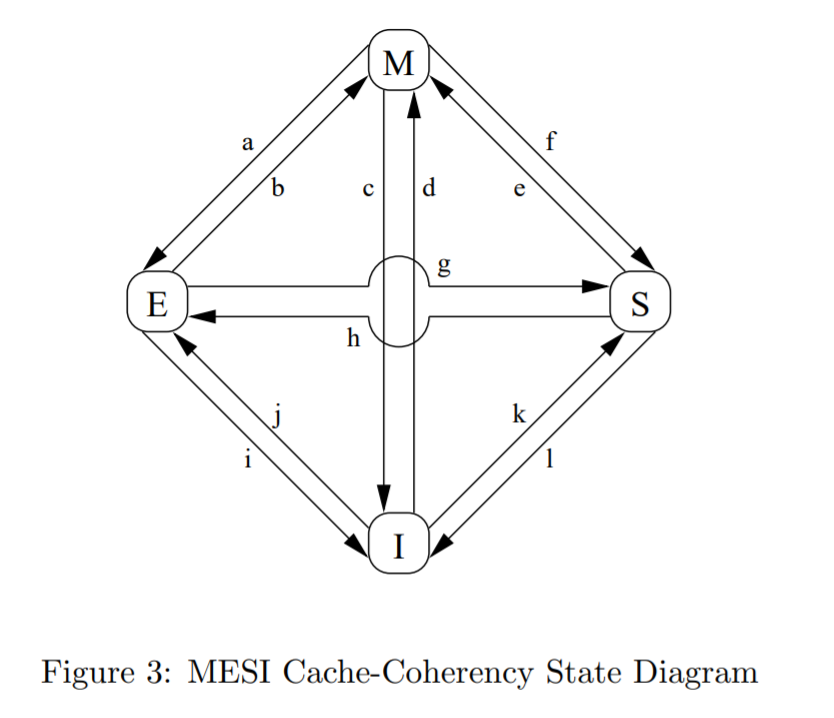
a. M->E一个缓存条已经写回了主存,但是这个CPU仍保留这条数据在自己的缓存中保留修改它的权力。这个状态转移需要发送“writeback”消息。
b. E->M CPU写了一个处于Exclusive状态的缓存条,这个转移不需要发送或接收任何消息。
c. M->I CPU收到了“read invalidate”消息,必须invalidate它的本地副本,然后回复”read response“和”invalidate acknowledge“消息。
d. I->M CPU对不存在在缓存的数据做了原子性的读-改-写操作,这种转移需要发送”read invalidate“,并且收到来自“read response”的数据。同样,CPU必须收到”invalidate acknowledge“来完成此操作。
e. M->S CPU没有通过原子性的读-改-写操作一个read-only缓存行,必须发送“invalidate”消息,而且必须等到所有invalidate acknowledge回复才能完成状态转移。
f. S->M 有其他的CPU读了这个缓存条,它会被CPU cache或者主存提供。无论怎样,CPU保留“read-only”副本。这个操作需要发送“read”消息。
g. E->S 有其他的CPU来读这个缓存行的数据,它可以被CPU cache或者主存提供。不管怎样,CPU保留ready-only副本。这个操作需要通过发送read来完成。
h. S->E cpu意识到它马上要写数据到cacheline,所以提前发出invalidate消息给其他cpu
i. E->I 其他cpu发来read invalidate
j. I->E cpu在写数据之前发出read invalidate消息给其他cpu,必须等到acknowledge回复才能进行后续处理。这条缓存行大概回转移到modified根据(b)S
k. I->S cpu发出read请求
l. S->I 收到invalidate请求
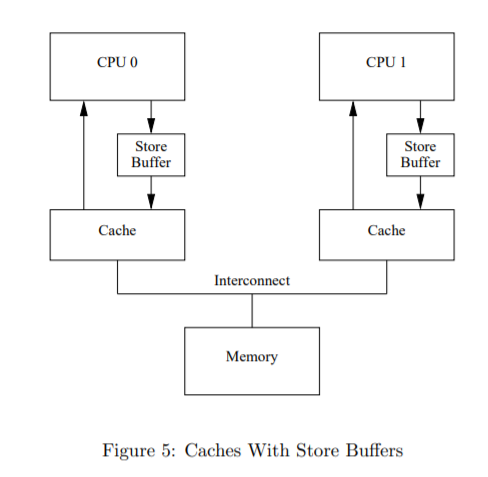
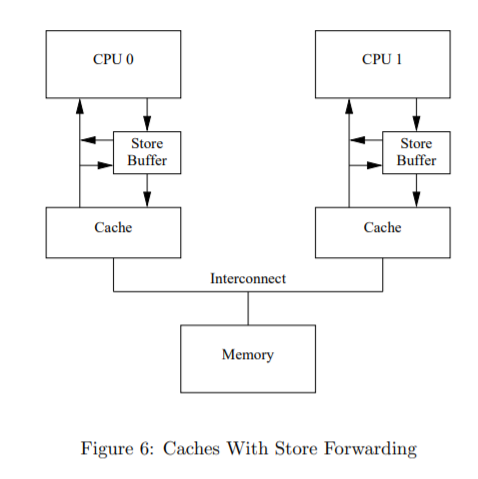
Store Buffer
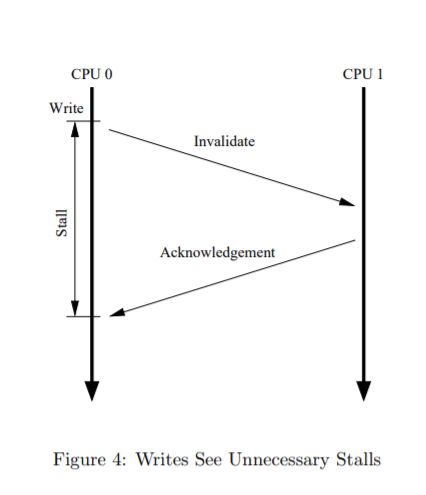
CPU在等待acknowledge的过程中需要长时间的阻塞:
防止不必要的写入停顿的一种方法是在每个CPU及其CPU之间添加“存储缓冲区”缓存。
要查看第一个复杂性,即违反自我一致性,请考虑以下代码,其变量“ a”和“ b”均初始为零,并且缓存行包含最初由CPU 1拥有的变量“ a”,而最初包含CPU 0的变量“ b”:
cpu0cache里面有个b,初值为0,cpu1cache有个a,初值为0,现在cpu0运行代码
a=1;
b=a+1;
assert(b==2)
cpu0执行a=1的时候发现本地cache没有a,所以发送read invalidate给cpu1,然后把a=1写入store buffer
cpu1收到read invalidate之后把a传给cpu0并且本地cacheline置为无效
cpu0开始执行b=a+1
cpu0收到cpu1的read response,发现a=0
cpu0执行a+1,得到1赋给b
cpu0执行最后一句,失败
这里关键的问题是cpu会把自己的操作看做是全局的内存操作,但其实操作storebuffer没有操作到主存,所以我们需要在查cache的时候还得查一下store buffer,这种技术叫做store forwarding.
void foo(void) {
a = 1;
b = 1;
}
void bar(void) {
while(b==0) continue;
assert(a==1);
}
同样的,cpu0cache里面有个b,初值为0,cpu1cache有个a,初值为0,现在cpu0运行foo, cpu1运行bar
cpu0 发现a不在本地cache,发送read invalidate去cpu1,并在store buffer中把a置为1
cpu1 执行while (b == 0)发现b不在本地内存,发送read消息去cpu0
cpu0 在本地cache置b为1
cpu0收到read消息,把cache中的b传送给cpu1,并把本地状态置为s
cpu1发现b为1,退出循环,因为这时候cpu1本地cache中a还是1,所以失败
cpu1收到read invalidate,把a传输给cpu0,并置本地cache为invalidate但是太晚了
cpu0收到cpu1关于a的read response,把本地的store buffer移到cache中
第一个问题硬件工程署可以解决,但是第二个很难处理,因为硬件无法知道变量之间的依赖关系,硬件工程师设计了memory barrier(内存屏障),软件可以使用这个工具来提示cpu变量之间的关系。新的代码如下:
void foo(void) {
a = 1;
smp_mb();
b = 1;
}
void bar(void) {
while(b==0) continue;
assert(a==1);
}
内存屏障smp_mb()提示cpu在进行smp_mb之后的存储的时候,会先把store buffer里的数据刷新到cache中。有两种方式,1:cpu会等到store buffer清空之后再处理其他指令,或者2:之后的所有写操作都不写到cache,而是写到store buffer中,直到smp_mb之前的store buffer中的数据刷新到cache中。
上例中的执行效果如下:
cpu0执行 a=1,发现a不在本地cache中,进而把a=1写入store buffer,并发出read invalidate消息给cpu1
cpu1执行while (b == 0),发现b不在本地cache中,进而发出read消息给cpu0
cpu0执行smp_mb,把store buffer中的a标记一下
cpu0执行b=1 发现状态为独占,所以可以直接写,但是因为store buffer中有标记过的值,所以把b=1写入store buffer,但是不标记
cpu0收到read消息,把cache中b的数据0发给cpu1,并把cacheline置为s
cpu1收到b=0,陷入循环中
cpu0收到read invalidate消息,进而把a=1从store buffer写入cache,这时候可以把store buffer中的b=1写入cache,但是发现这时候cache中的b属于s状态,所以发出invalidate消息给cpu1
cpu1收到invalidate消息之后把b设为1
cpu0收到invalidate ack之后把b的值1写入cache
cpu1要读取b的值,发出read消息给cpu0,
cpu0把b=1发给cpu1
cpu1收到b的值1,退出循环
cpu1发现a无效,发出read消息给cpu0
cpu0把a的值1发送给cpu1,并且把a置为s
cpu1得到a=1,成功
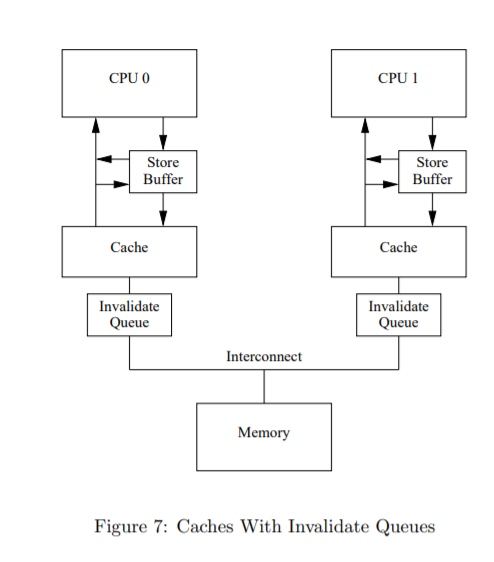
但是内存屏障的处理方法有个问题,那就是store buffer空间是有限的,如果store buffer中的空间被smp_mb之后的存储塞满,cpu还是得等待invalidate消息返回才能继续处理。解决这种问题的思路是让invalidate ack能更早得返回,一种办法是提供一种放置invalidate message的队列,称为invalidate queue. cpu可以在收到invalidate之后马上返回invalidate ack,而不是在把本地cache invalidate之后,并把invalidate message放置到invalide queue,以待之后处理。
void foo(void) {
a = 1;
smp_mb();
b = 1;
}
void bar(void) {
while(b==0) continue;
smp_mb();
assert(a==1);
}
在assert之前插入内存屏障,作用是把invalidate queue标记下,在读取下面的数据的时候,譬如a的时候会先把invalidate queue中的消息都处理掉,这里的话会使得a失效而去cpu0获取最新的数据。
Advice to Hardware Designers
-
忽略缓存一致性的I / O设备。
这种引人入胜的错误功能可能导致内存中的DMA丢失对输出缓冲区的最新更改,或者同样糟糕的是,在DMA完成之后,导致输入缓冲区被CPU缓存的内容覆盖。为了使系统在这种不当行为下工作,在将缓冲区提供给I / O设备之前,必须仔细刷新任何DMA缓冲区中任何位置的CPU缓存。即使这样,也需要非常小心,避免出现指针错误,因为即使对输入缓冲区的读取错误放置,也可能导致数据输入损坏!
-
忽略缓存一致性的设备中断。
这听起来可能很无辜-毕竟,中断不是内存引用,不是吗?但是,想象一下一个具有拆分缓存的CPU,其中一个存储库非常繁忙,因此保持输入缓冲区的最后一个缓存行。如果相应的I / O完成中断到达此CPU,则该CPU的内存对缓冲区最后缓存行的引用可能返回旧数据,再次导致数据损坏,但其形式在以后的崩溃转储中将不可见。等到系统开始转储有问题的输入缓冲区时,DMA很可能已经完成。