状态检索——快速判断一个用户是否存在
如果我们要查询的对象ID本身是正整数类型,而且ID范围有上限的话,我们可以直接用用户ID的值作为下标,id存在为1,不存在为1。如果用4个字节存储0和1会造成巨大的浪费。
使用位图来减少存储空间
如果我们能以 bit 为单位来构建这个数组,那使用空间就是 int 32 数组的 1/32,从而大幅减少了存储使用的内存空间。这种以 bit 为单位构建数组的方案,就叫作 Bitmap,翻译为位图。但是很多操作系统并不支持位图这样的数据结构。
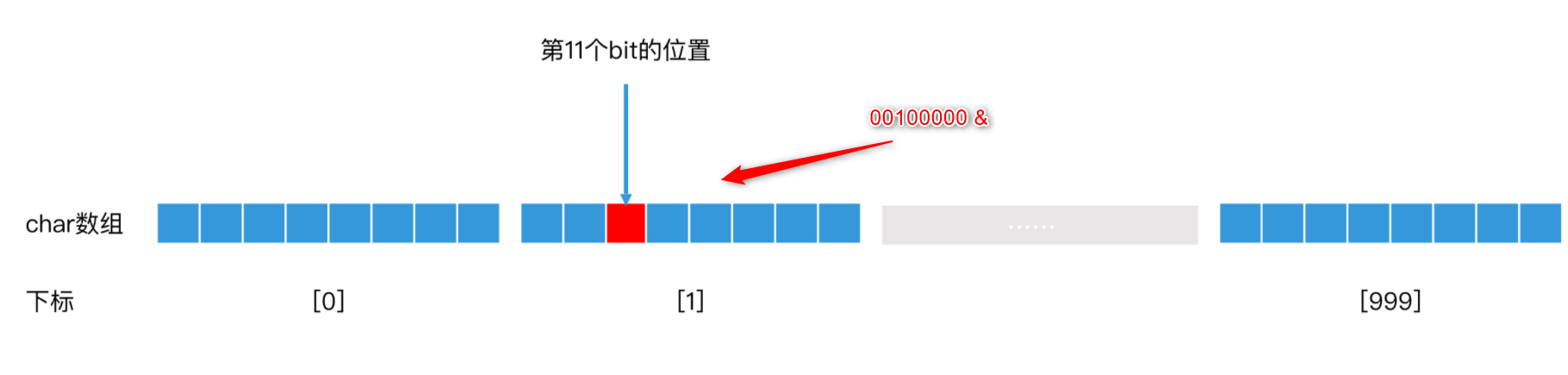
我们以 char 类型的数组为例子。假设我们申请了一个 1000 个元素的 char 类型数组,每个 char 元素有 8 个 bit,如果一个 bit 表示一个用户,那么 1000 个元素的 char 类型数组就能表示 8*1000 = 8000 个用户。如果一个用户的 ID 是 11,那么位图中的第 11 个 bit 就表示这个用户是否存在的信息。如何快速访问到第11个bit:
- 一个元素占8个bit,11%8=3并且11/8=1,这意味着第11个bit存在于第二个元素里的第3个bit。
- 构造一个00100000的字节,然后和第二个元素做and运算,得出元素是1还是0。一共花费两次O(1)的操作。
bitmap有自己的压缩方法:roaring bitmap
除了位图外,我们还可以使用布隆过滤器来实现空间的优化。因为用来存储id的数组所占的空间其实就是 数组元素个数*每个元素大小。如果联想到之前的HashMap,我们可以通过限制数组长度来优化数组元素个数。
如果我们希望将数组长度压缩到一个足够小的值之内,我们就需要通过hash将大于数组长度的用户id,转换为一个小于数组长度的数值作为下标。Hash带来的另一个优点就是不需要把用户ID限制为正整数了,可以是字符串。
数组压缩的越小,发生哈希冲突的可能性就越大。如何在数组压缩的情况下缓解哈希冲突,并且保证查询的正确性,是我们面临的主要问题。
之前我们提到了”双散列”的优化方案,它的原理是通过多个hash函数来解决冲突问题。这其实也是布隆过滤器(Bloom Filter)的设计思想。
布隆过滤器是一种概率性数据结构(probabilistic data structure)它最大的特点,就是对一个对象使用多个哈希函数。如果我们使用了 k 个哈希函数,就会得到 k 个哈希值,也就是 k 个下标,我们会把数组中对应下标位置的值都置为 1。布隆过滤器和位图最大的区别就在于,我们不再使用一位来表示一个对象,而是使用 k 位来表示一个对象。这样两个对象的 k 位都相同的概率就会大大降低,从而能够解决哈希冲突的问题了。
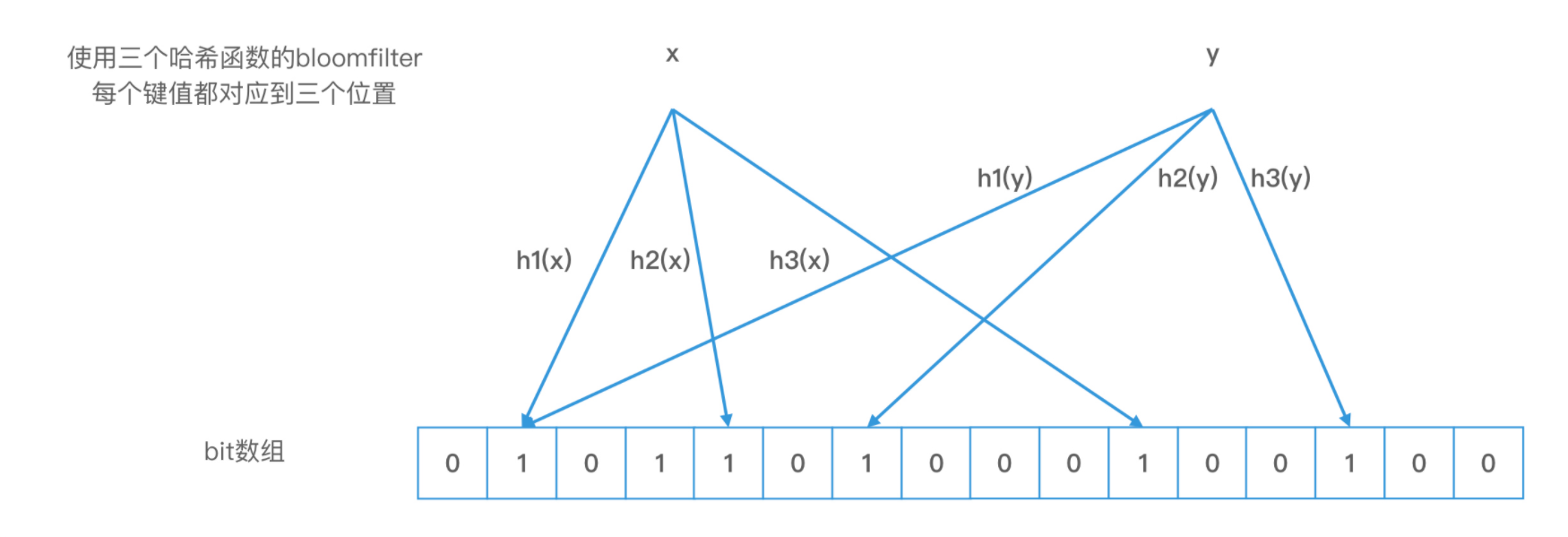
但是,布隆过滤器的查询有一个特点,就是即使任何两个元素的哈希值不冲突,而且我们查询对象的 k 个位置的值都是 1,查询结果为存在,这个结果也可能是错误的。这就叫作布隆过滤器的错误率。
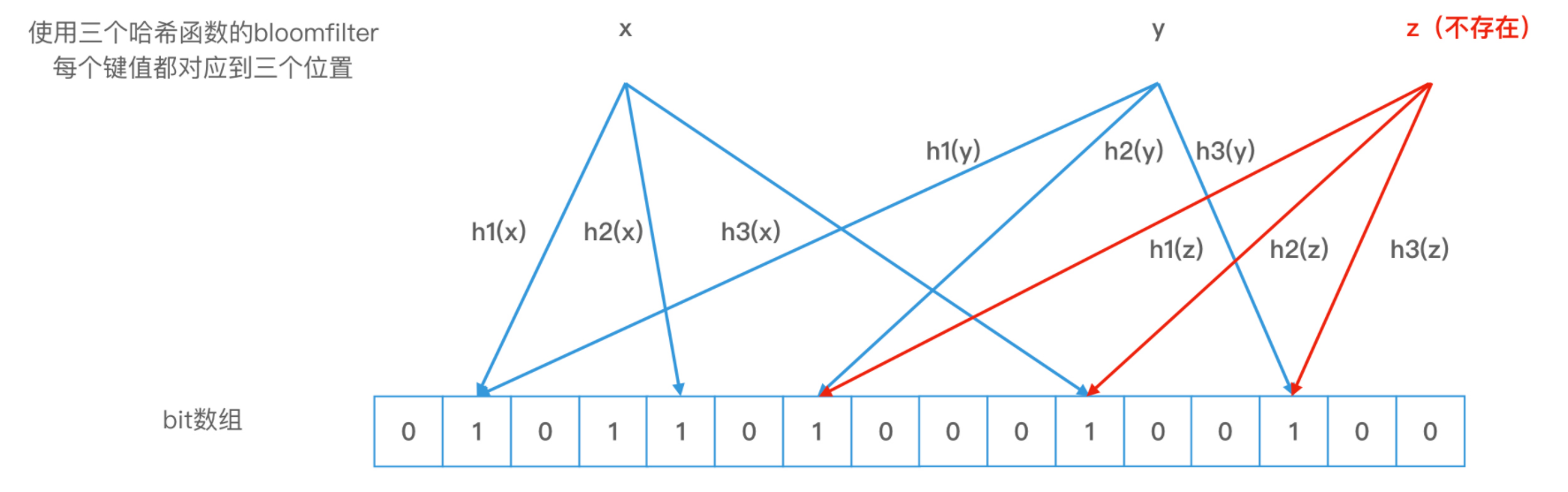
根据定义,布隆过滤器可以检查值是 “可能在集合中” 还是 “绝对不在集合中”。“可能” 表示有一定的概率,也就是说可能存在一定为误判率。这个误判率(FPP)是可预测的。
实际情况中,布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过公式计算。
那遇到“可能存在”这样的情况,我们该怎么办呢?不要忘了我们的使用场景:我们希望用更小的代价快速判断 ID 是否已经被注册了。在这个使用场景中,就算我们无法确认 ID 是否已经被注册了,让用户再换一个 ID 注册,这也不会损害新用户的体验。在系统不要求结果 100% 准确的情况下,我们可以直接当作这个用户 ID 已经被注册了就可以了。这样,我们使用布隆过滤器就可以快速完成“是否存在”的检索。
有这样一个计算最优哈希函数个数的数学公式: 哈希函数个数 k = (m/n) * ln(2)。其中 m 为 bit 数组长度,n 为要存入的对象的个数。实际上,如果哈希函数个数为 1,且数组长度足够,布隆过滤器就可以退化成一个位图。所以,我们可以认为“位图是只有一个特殊的哈希函数,且没有被压缩长度的布隆过滤器”。 \(k次hash某一bit位未被置为1的概率为: (1-\frac{1}{m})^k \\ 插入n个元素后依旧为0的概率和为1的概率分别是:\\ (1-\frac{1}{m})^{nk}, 1- \left( 1-\frac{1}{m} \right)^{nk}\) 标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 1,但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定 \(\left[ 1- \left( 1-\frac{1}{m} \right)^{nk} \right]^{k}\approx\left( 1-e^{-kn/m} \right)^{k}\) 选择k和m的值: \(m = - \frac{n\ln{p}}{(ln{2})^{2}} \\ k = \frac{m}{n}\ln{2}\)
- n 是已经添加元素的数量;
- k 哈希的次数;
- m 布隆过滤器的长度(如比特数组的大小)
实践
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。 除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
Q&A
如果位图中一个元素被删除了,我们可以将对应 bit 位置为 0。但如果布隆过滤器中一个元素被删除了,我们直接将对应的 k 个 bit 位置为 0,会产生什么样的问题呢?为什么?
传统的Bloom Filter不支持删除。但是名为 Counting Bloom filter的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。
布隆过滤器 vs 原始位图: 原始位图要存一个int 32的数,就要先准备好512m的空间的长数组。布隆过滤器不用这么长的数组,因此比原始位图省空间。 布隆过滤器 vs 哈希表: 假设布隆过滤器数组长度和哈希表一样。但是哈希表存的是一个int 32,而布隆过滤器存的是一个bit,因此比同样长度的哈希表省空间。 当然,如果哈希表也改为只存一个bit的数组,那么他们的大小是一样的。这时候就是你说的多个哈希函数的作用场景了。 其实,你会发现,只存一个bit的哈希表,其实也可以看做是只有一个哈希函数的布隆过滤器。很多时候,布隆过滤器,哈希表,还有位图,它们的边界是模糊的。我们最重要的是了解清楚他们的特点,知道在什么场景用哪种结构就好了。
布隆过滤器 vs roaring bitmap: 所有的设计都是trade off。roaring bitmap尽管压缩率很高,还支持精准查找,但是它放弃的是速度。高16位是采用二分查找,array container也是二分查找。因此,在这一点上布隆过滤器是有优势的。此外,它还不能保证压缩空间,它的空间会随着元素增多而变大,极端情况下恢复回bitmap。 而布隆过滤器保持了高效的查找能力和空间控制能力,但是放弃了精准查找能力,精准度会随着元素增多而下降。 因此,尽管都是对bitmap进行压缩,但是两者的设计思路不一样,使用场景也不同。在不要求精准,但是要求快速和省空间的场景下,布隆过滤器是不错的选择。
如何确定BloomFilter和BitMap的大小:
如果是原始位图,假设id是int 32,如果你不清楚数值分布范围,那么只能覆盖所有int 32的取值区间。这时候的位图大小是512m。
如果是布隆过滤器,你需要预估你的用户数量, 此外,还要设置一个你能接受的错误率p,使用这个公式:m =-n ln p / (ln 2)^2 ,可以算出来bit 位数组m的大小。