倒排索引——从海量数据中查询同时带有A和B的文档
正排索引
我们先来看比较简单的那个问题:给出一首诗的题目,马上背出内容。这其实就是一个典型的键值查询场景。针对这个场景,我们可以给每首诗一个唯一的编号作为 ID,然后使用哈希表将诗的 ID 作为键(Key),把诗的内容作为键对应的值(Value)。这样,我们就能在 O(1) 的时间代价内,完成对指定 key 的检索。这样一个以对象的唯一 ID 为 key 的哈希索引结构,叫作正排索引(Forward Index)。
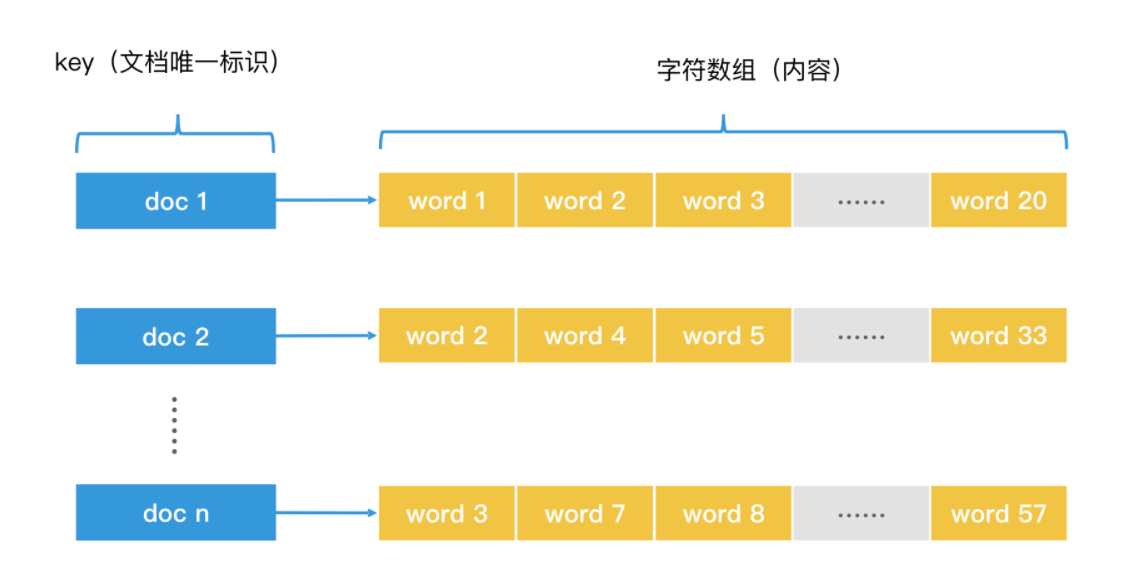
一般来说,我们会遍历哈希表,遍历的时间代价是 O(n)。在遍历过程中,对于遇到的每一个元素也就是每一首诗,我们需要遍历这首诗中的每一个字符,才能判断是否包含“极”字和“客”字。假设每首诗的平均长度是 k,那遍历一首诗的时间代价就是 O(k)。这样的代价非常之高。
我们将每个关键字当作 key,将包含了这个关键字的诗的列表当作存储的内容。这样,我们就建立了一个哈希表,根据关键字来查询这个哈希表,在 O(1) 的时间内,我们就能得到包含该关键字的文档列表。这种根据具体内容或属性反过来索引文档标题的结构,我们就叫它倒排索引(Inverted Index)。在倒排索引中,key 的集合叫作字典(Dictionary),一个 key 后面对应的记录集合叫作记录列表(Posting List)。
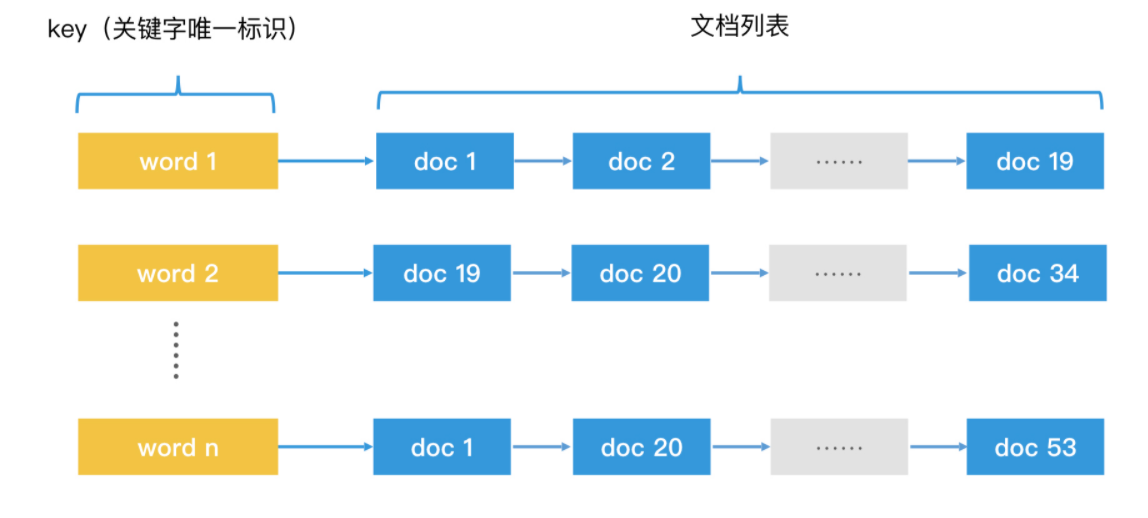
如何创建倒排索引
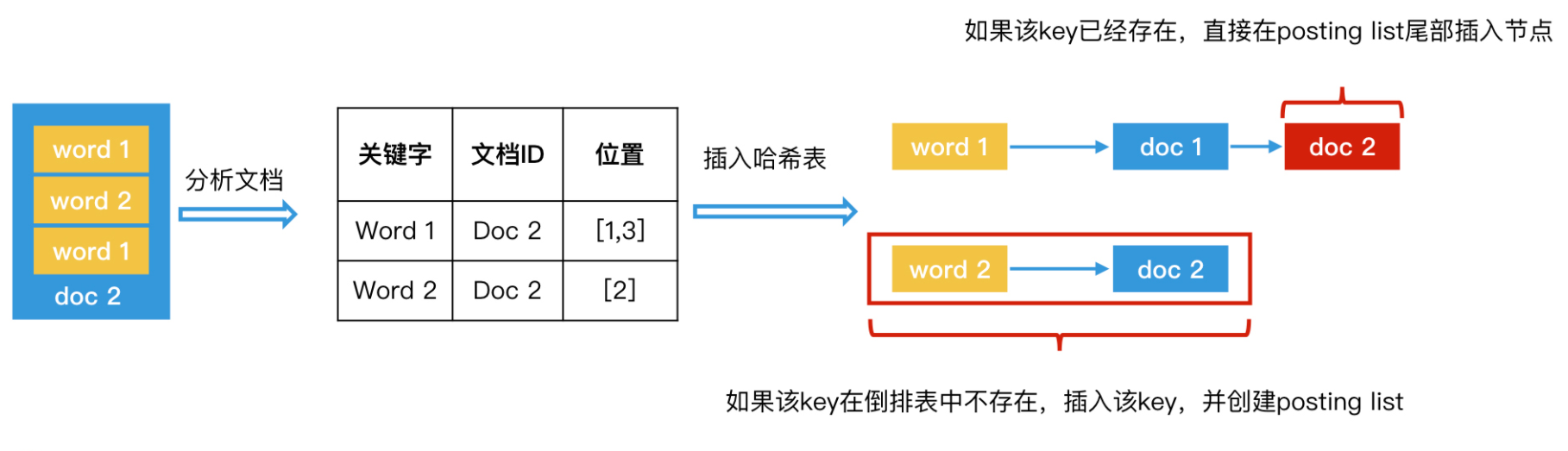
- 每个文档都应该有一个唯一标识符,先排序,然后开始遍历文档。为什么要排序?
- 排序之后可以保证了在某两个word的posting list的查询。
- 解析当前文档中的每个关键字,生成<关键字,文档ID,关键字位置>这样的数据对。为什么要记录关键字位置?
- 在组合查询时需要判断多个关键字之间是否足够近。
- 将关键字作为key插入哈希表。如果哈希表已经有这个key了,就是posting list后面追加节点,记录文档ID。
- 重复第2和第3步,处理完所有文档,完整倒排索引的创建。
倒排索引的查询
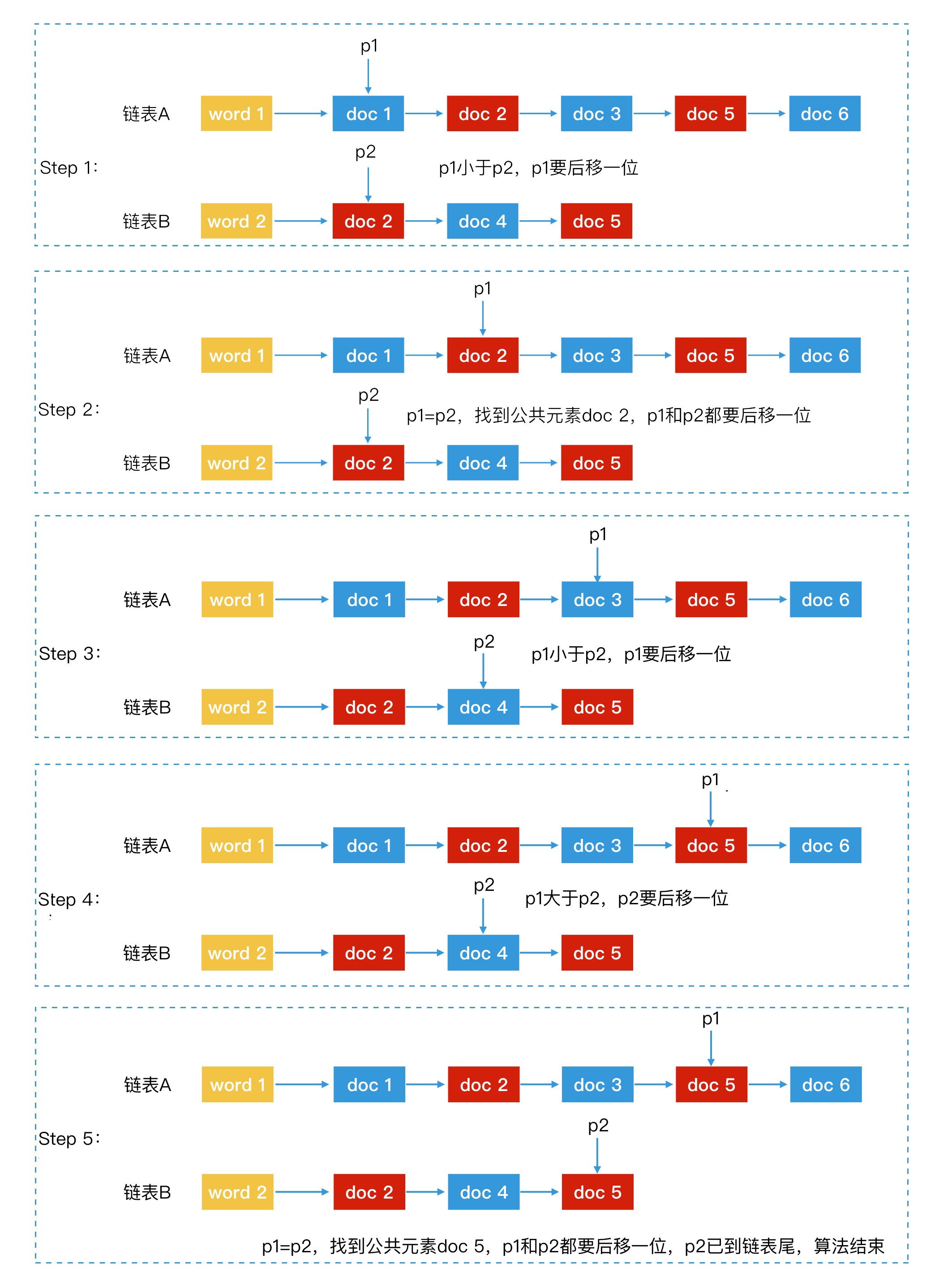
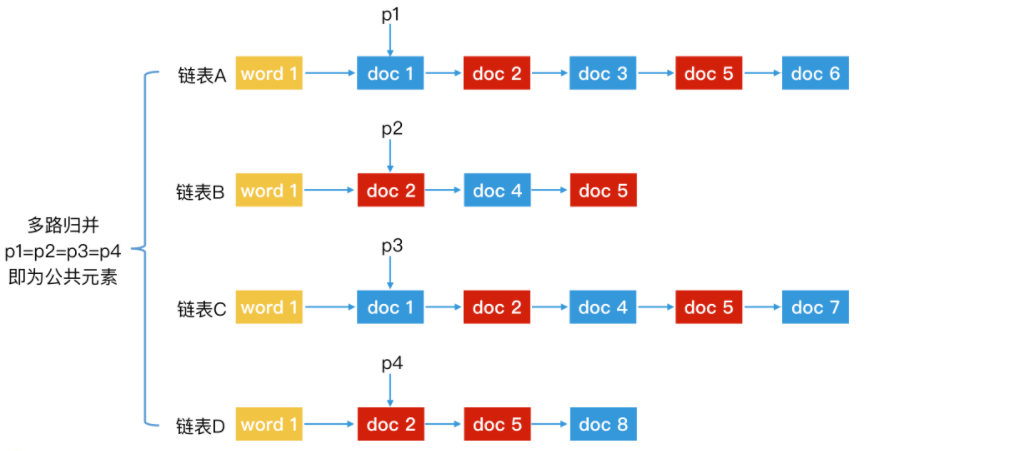
我们该如何在 A 和 B 这两个链表中查找出公共元素呢?如果 A 和 B 都是无序链表,那我们只能将 A 链表和 B 链表中的每个元素分别比对一次,这个时间代价是 O(m*n)。但是,如果两个链表都是有序的,我们就可以用归并排序的方法来遍历 A 和 B 两个链表,时间代价会降低为 O(m + n),其中 m 是链表 A 的长度,n 是链表 B 的长度。
归并过程为:
- 使用指针 p1 和 p2 分别指向有序链表 A 和 B 的第一个元素。
- 对比 p1 和 p2 指向的节点是否相同,这时会出现 3 种情况:
- 两者的 id 相同,说明该节点为公共元素,直接将该节点加入归并结果。然后,p1 和 p2 要同时后移,指向下一个元素;
- p1 元素的 id 小于 p2 元素的 id,p1 后移,指向 A 链表中下一个元素;
- p1 元素的 id 大于 p2 元素的 id,p2 后移,指向 B 链表中下一个元素。
- 重复第 2 步,直到 p1 或 p2 移动到链表尾为止。
那对于两个 key 的联合查询来说,除了有“同时存在”这样的场景以外,其实还有很多联合查询的实际例子。比如说,我们可以查询包含“极”或“客”字的诗,也可以查询包含“极”且不包含“客”的诗。这些场景分别对应着集合合并中的交集、并集和差集问题。它们的具体实现方法和“同时存在”的实现方法差不多,也是通过遍历链表对比的方式来完成的。
多个key联合查询:
Q&A
对于一个检索系统而言,除了根据关键字查询文档,还可能有其他的查询需求。比如说,我们希望查询李白都写了哪些诗。也就是说,如何在“根据内容查询”的基础上,同时支持“根据作者查询”,我们该怎么做呢?
- 用不同的key进行区分: “作者_李白”=[“将进酒”,”凤求凰”,”静夜思”]
- 或者在posting list中加域用来表明作者。
Questions
假设有一个员工管理系统,它存储了用户的 ID、姓名、所属部门等信息。如果我们需要它支持以下查询能力:
- 根据员工 ID 查找员工信息,并支持 ID 的范围查询;
- 根据姓名查询员工信息;
- 根据部门查询部门里有哪些员工。
如何实现这两个功能。
这道题中其实有一个隐含的问题:员工信息应该如何存储?由于员工名单本身就是一个列表,而且一般来说,员工的ID都是递增且有序的。因此,我们可以使用线性结构来存储员工信息,比如说,使用一个足够大的数组。在这个数组中,每一个元素都是一个结构体,存储了一个员工的所有信息。
当新入职一个员工的时候,我们只需要往数组尾部空闲位置插入一个信息即可。由于新员工ID是递增的,因此数组依然有序。
如果有员工离职,那我们可以借鉴哈希表中删除元素的设计思想,不真正从数组中直接删除该员工信息,而是加上一个“已离职”的标志,这样就避免了要实时挪动数组的代价。我们可以等到系统处于空闲状态时,再做一次统一清理。当然,如果离职的员工不多,我们直接挪动数组也是可以的,这并不是一个需要频繁更改的操作。
对于第二个问题,根据姓名查询员工信息,我们需要再额外建立一个索引。如果员工的姓名都是独一无二的,那么使用哈希表就可以很好地查找。但如果担心员工姓名有重复,那我们可以将哈希表升级为倒排表,我们以员工的姓名为key,对应的posting list为员工ID列表。这样,这个索引就不需要存储每一个员工的详细信息,而是通过两步查询的方式完成。第一步:以姓名为key,在哈希表中查找到这个姓名对应的ID(或ID列表);第二步,到存储所有员工的数组中,以ID为key,查找到这个员工的详细信息。
第三个问题是一个典型的倒排索引场景。每个部门都会有多名员工。因此,我们可以以部门ID(或者部门名)为key,建立倒排索引。而posting list中,则存了该部门所有员工的ID。
这样,我们通过建立一个有序数组作为基础,再建立一个哈希(或倒排表)完成姓名查询,一个倒排表完成部门查询,这样就可以同时解决这三个检索问题。你会发现,现实中的系统往往会同时使用多个索引,以解决不同的检索需求。
[Why are skip lists not preferred over B+-trees for databases?]