倒排检索加速1:工业界如何利用跳表、哈希表、位图进行加速
在许多大型系统中,倒排索引是最常用的检索技术,搜索引擎、广告引擎、推荐引擎等都是基于倒排索引技术实现的。而在倒排索引的检索过程中,两个 posting list 求交集是一个最重要、最耗时的操作。
跳表法加速倒排索引
倒排索引中的 posting list 一般是用链表来实现的。当两个 posting list A 和 B 需要合并求交集时,如果我们用归并法来合并的话,时间代价是 O(m+n)。其中,m 为 posting list A 的长度,n 为 posting list B 的长度。
假设 posting list A 中的元素为 <1,2,3,4,5,6,7,8……,1000>,这 1000 个元素是按照从 1 到 1000 的顺序递增的。而 posting list B 中的元素,只有 <1,500,1000>3 个。那按照我们之前讲过的归并方法,它们的合并过程就是,在找到相同元素 1 以后,还需要再遍历 498 次链表,才能找到第二个相同元素 500。
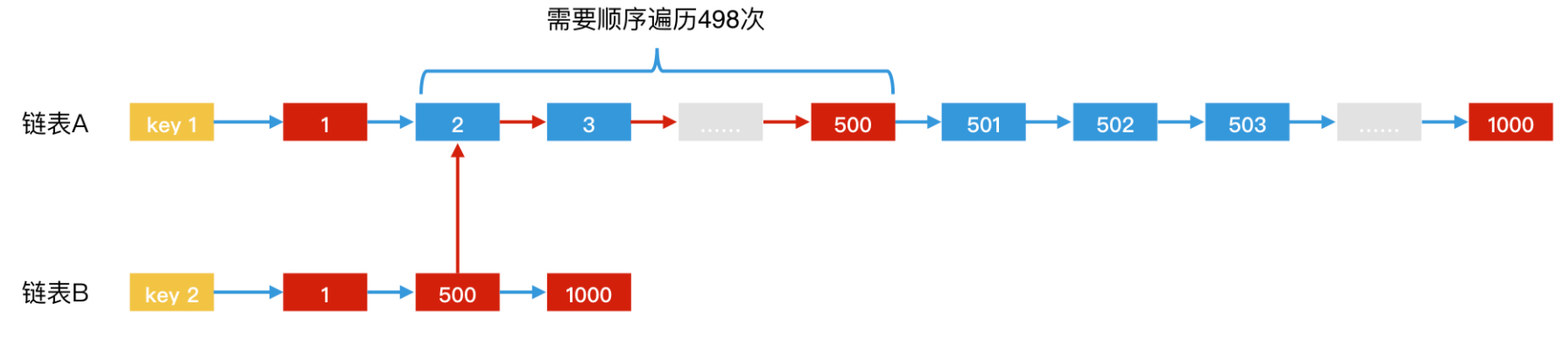
很显然,为了找到一个元素,遍历这么多次是很不划算的。我们可以将链表改为跳表。这样,在 posting list A 中,我们从第 2 个元素遍历到第 500 个元素,只需要 log(498) 次的量级,会比链表快得多。
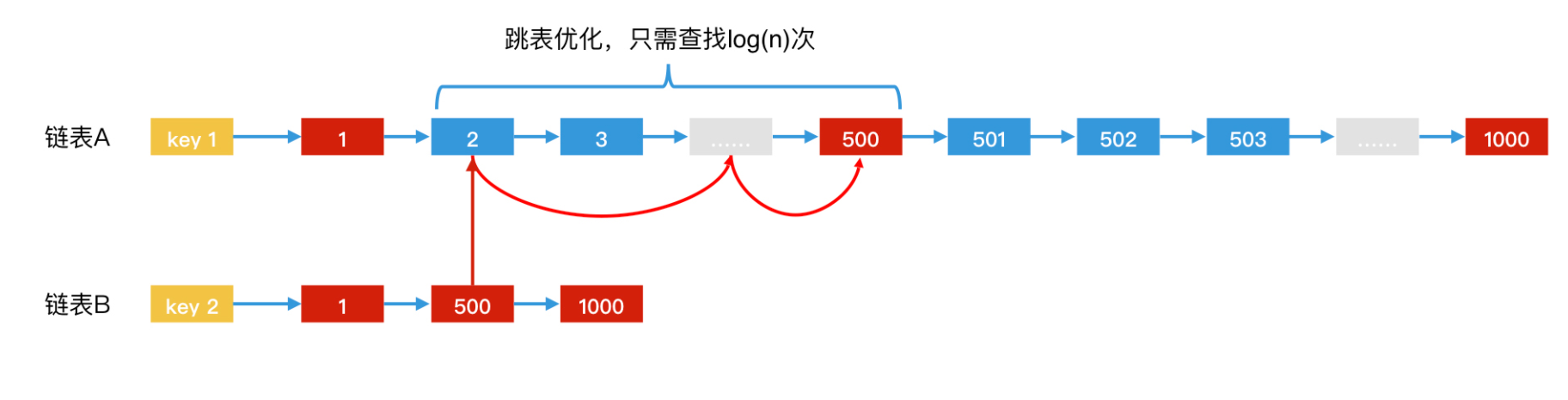
在寻找 500 这个公共元素的过程中,我们是拿着链表 B 中的 500 作为 key,在链表 A 中进行跳表二分查找的。但是,在查找 1000 这个公共元素的过程中,我们是拿着链表 A 中的元素 1000,在链表 B 中进行跳表二分查找的。这就是相互二分查找。
你可以这么理解:如果 A 中的当前元素小于 B 中的当前元素,我们就以 B 中的当前元素为 key,在 A 中快速往前跳;如果 B 中的当前元素小于 A 中的当前元素,我们就以 A 中的当前元素为 key,在 B 中快速往前跳。这样一来,整体的检索效率就提升了。
在实际的系统中,如果 posting list 可以都存储在内存中,并且变化不太频繁的话,那我们还可以利用可变长数组来代替链表——当数组被写满时,直接申请一个2倍于原数组的新数组,将原数组数据直接导入新数组中。
那对于两个 posting list 求交集,我们同样可以先使用可变长数组,再利用相互二分查找进行归并。而且,由于数组的数据在内存的物理空间中是紧凑的,因此 CPU 还可以利用内存的局部性原理来提高检索效率。
哈希表加速倒排索引
求交集时,如果一个集合特别大,另一个集合相对比较小,那我们就可以用哈希表来存储大集合。这样,我们就可以拿着小集合中的每一个元素去哈希表中对比:如果查找为存在,那查找的元素就是公共元素;否则,就放弃。
我们还是以前面说的 posting list A 和 B 为例,来进一步解释一下这个过程。由于 Posting list A 有 1000 个元素,而 B 中只有 3 个元素,因此,我们可以将 posting list A 中的元素提前存入哈希表。这样,我们利用 B 中的 3 个元素来查询的时候,每次查询代价都是 O(1)。如果 B 有 m 个元素,那查询代价就是 O(m)。
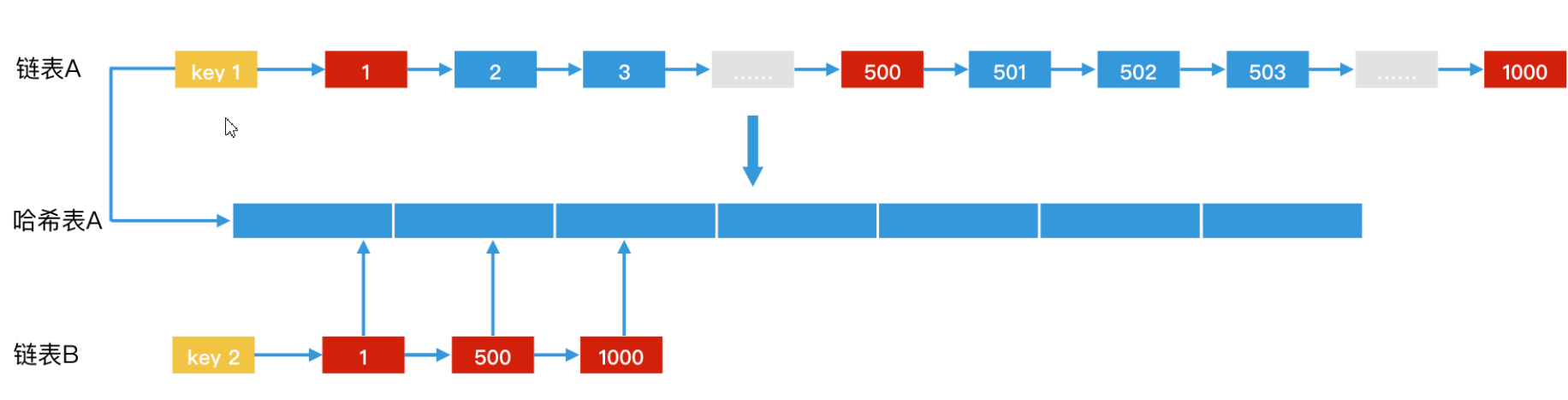
这里的前提是,在查询前就把posting list转为哈希表,这就需要我们提前分析,哪些posting list经常会被拿来求交集,针对这一批posting list,我们将它们存入哈希表。从而实现加速。
为什么原始的posting list也要保留?我们假设有这样一种情况:当我们要给两个 posting list 求交集时,发现这两个 posting list 都已经转为哈希表了。这个时候,由于哈希表没有遍历能力,反而会导致我们无法合并这两个 posting list。因此,在哈希表法的最终改造中,一个 key 后面会有两个指针,一个指向 posting list,另一个指向哈希表(如果哈希表存在)。
除此之外,哈希表法还需要在有很多短 posting list 存在的前提下,才能更好地发挥作用。这是因为哈希表法的查询代价是 O(m),如果 m 的值很大,那它的性能就不一定会比跳表法更优了。
位图法加速倒排索引
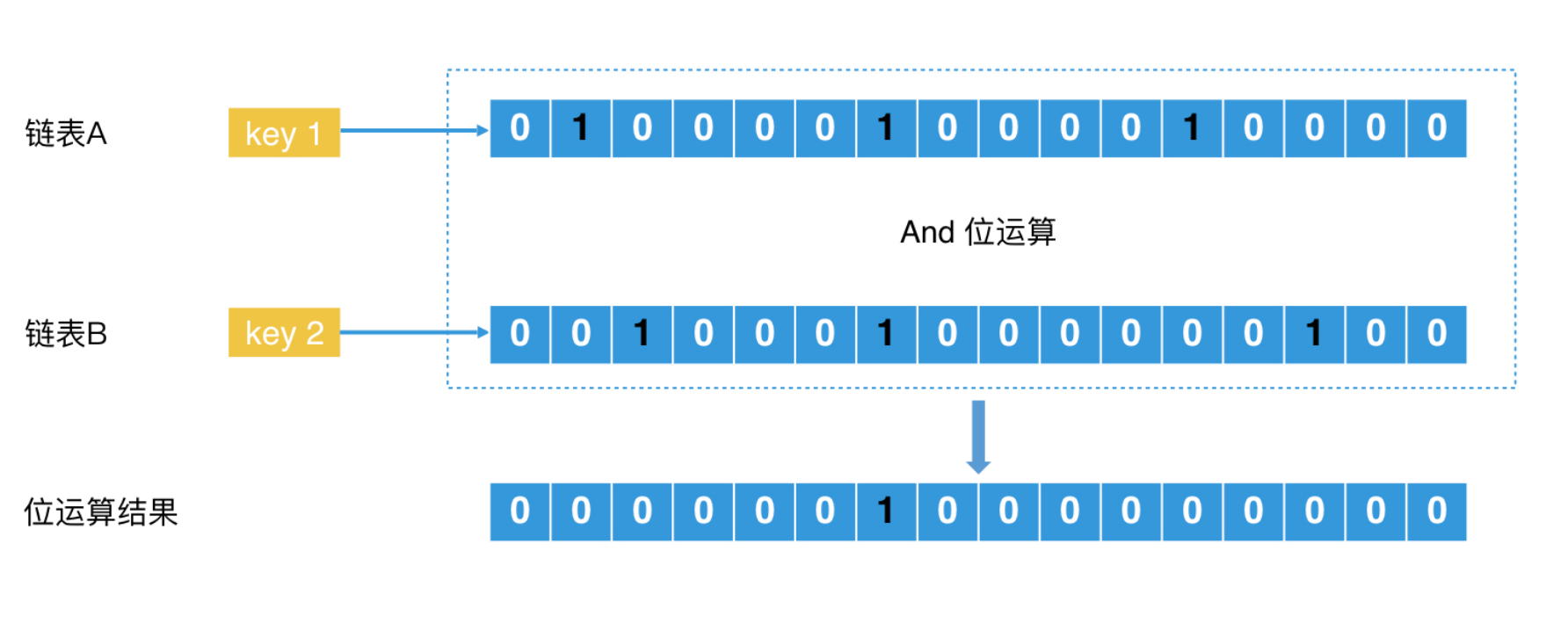
我们需要为每个key生成同样长度的位图,表示所有的对象空间。如果以个元素出现在该posting list中,我们就将位图中该元素对应的位置置为1.这样就完成了posting list的位图改造。
如果要查找 posting list A 和 B 的公共元素,我们可以将 A、B 两个位图中对应的位置直接做 and 位运算。由于位图的长度是固定的,因此两个位图的合并运算时间代价也是固定的。CPU执行位运算的效率非常快,因此,在长度不是特别长的情况下,位图法的检索效率还是非常高的。
位图的局限:
- 仅适用于值存储ID’的简单的posting list,如果是复杂对象就不适合用位图来存储了。假设一个word在文章的好几个位置都出现,用位图表示代价太高。
- 适用于posting list元素稠密的场景,如果posting list稀疏,使用位图的开销反而比链表更大。
- 占用大量空间,尽管位图只用一个bit就能表示元素是否存在,但每个posting list都需要表示完整的对象空间。如果 ID 范围是用 int32 类型的数组表示的,那一个位图的大小就约为 512M 字节。如果我们有 1 万个 key,每个 key 都存一个这样的位图,那就需要 5120G 的空间了。2^32 bit = 2^29 bytes = 2^19 kb = 2^9 mb = 512M
升级版位图:Roaring Bitmap
RBM数据结构
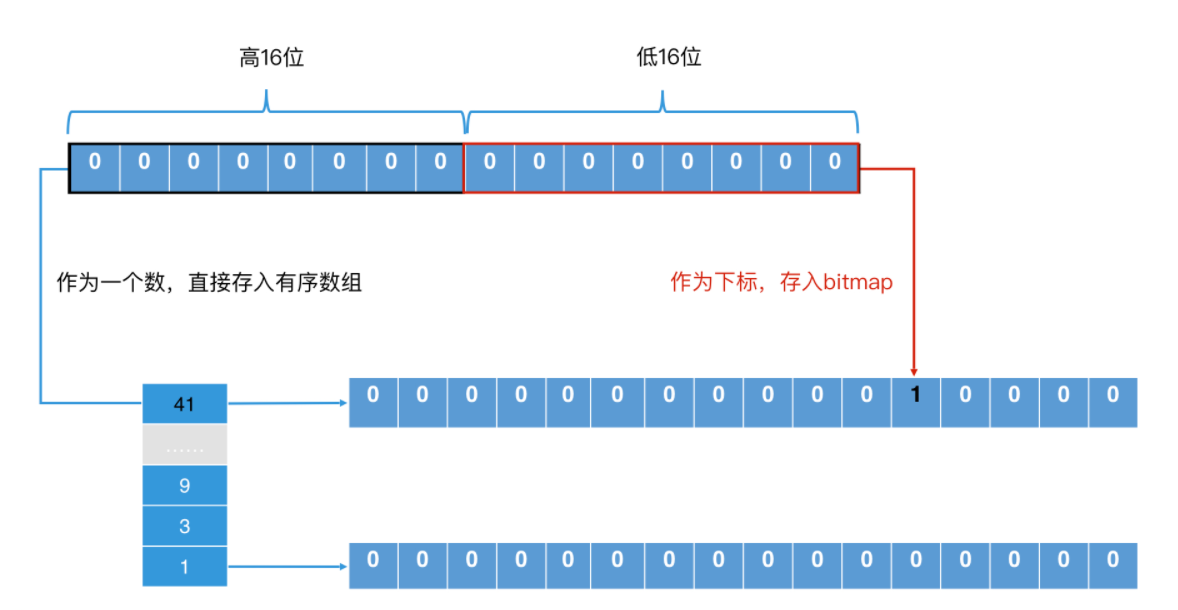
首先,Roaring Bitmap 将一个 32 位的整数分为两部分,一部分是高 16 位,另一部分是低 16 位。对于高 16 位,Roaring Bitmap 将它存储到一个有序数组中,这个有序数组中的每一个值都是一个“桶”;而对于低 16 位,Roaring Bitmap 则将它存储在一个 2^16 的位图中,将相应位置置为 1。这样,每个桶都会对应一个 2^16 的位图。
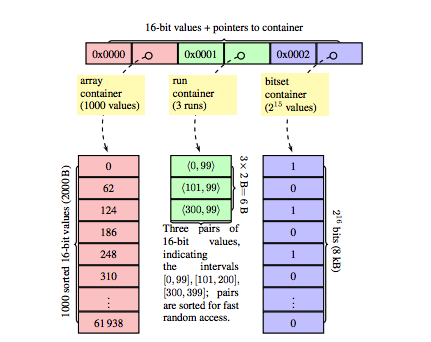
Roaring Bitmaps思路是将取值范围分片,每片大小相同,可容纳2^16个数。根据范围内实际数据的个数/分布选择最紧凑的存储形式:
- 区间内数据较多,且分布零散,则选择(未压缩)位图
- 区间内数据较少,且分布零散,则选择使用有序数组
- 区间内数据连续分布,则选择用Run Length Encoding编码
- input data: AAAAAAFDDCCCCCCCAEEEEEEEEEEEEEEEEE
- output data: 6A1F2D7C1A17E
-
第一层称之为Chunk,每个Chunk表示该区间取值范围的base(n2^16, 0<= n < 2^16),如果该取值范围内没有数据则Chunk不会创建
-
第二层称之为Container,会依据数据分布进行创建(Container内的值实际是区间内的offset)
-
- Roaring并不是一种静态数据结构,随着数据的增删,Container选择的存储格式也会随之自动调整
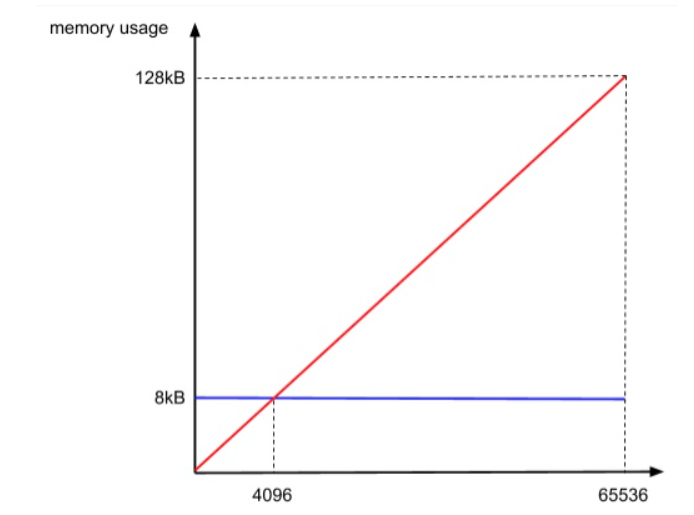
想象一个极端 的例子,一个 posting list 中,所有元素的高 16 位都是相同的,那在有序数组部分,我们只需要一个 2 个字节的桶(注:每个桶都是一个 short 型的整数,因此只有 2 个字节。如果数组提前分配好了 2^16 个桶,那就需要 128K 字节的空间,因此使用可变长数组更节省空间)。在低 16 位部分,因为位图长度是固定的,都是 2^16 个 bit,那所占空间就是 8K 个字节。可变长度数组大大节省了空间。
如果一个桶中存储的数据少于 4096 个,我们就不使用位图,而是直接使用 short 型的有序数组存储数据。同时,我们使用可变长数组机制,让数组的初始化长度是 4,随着元素的增加再逐步调整数组长度,上限是 4096。这样一来,存储空间就会低于 8K,也就小于使用位图所占用的存储空间了。
- 当区间内数量少于4096时,数组占用更紧凑;多于4096,则使用位图更经济
Roaring 提供O(logn)的查找性能:
-
首先二分查找key值的高16位是否在分片(chunk)中
-
如果分片存在,则查找分片对应的Container是否存
-
- 如果Bitmap Container,查找性能是O(1)
- 其它两种Container,需要进行二分查找
有序数组和位图用倒排索引结合起来的设计思路是能够保证高效检索的。
Roaring Bitmap 插入有三种情况:
- 第一种,在一个桶中刚插入数据时,因为数据量少,所以我们就默认使用数组容器;
- 第二种,随着数据插入,桶中的数据不断增多,当数组容器中的元素个数大于 4096 个时,就从数组容器转为位图容器;
- 第三种,随着数据的删除,如果位图容器中的元素个数小于 4096 个,就退化回数组容器。
RBM求交集
假设有Roaring Bitmap表示的两个集合A和B,如何求交集:
- 比较高16位的所有桶,也就是对这两个有序数组求交集,所有相同的桶会被留下来。
- 对相同的桶里面的元素求交集。有三种情况:
- 位图和位图求交集,直接用AND位运算。
- 数组和数组求交集,相互二分查找
- 位图和数组求交集,可以通过遍历数组在位图中查找数组中的每个元素是否存在(类似哈希表)。
Q&A
在 Roaring Bitmap 的求交集过程中,有位图和位图求交集、数组和数组求交集、位图和数组求交集这 3 种场景。那它们求交集以后的结果,我们是应该用位图来存储,还是用数组来存储呢?
1.位图和位图求交集 要对两个位图的交集做预判,如果预判数据大于 4096 就用位图,如果小于 4096 就用数组,当然预判肯定会有误判率,不过没关系,即使误判错多做一次转换就行了
假设位图1有 n1 个值, 位图1 有 n2 个值,位图的空间位 2 ** 16 = 65536 这里进行预判的时候可以认为是均匀分布的: 那么对于位图1 可以认为间隔 65536 / n1 个位有个值,位图2 可以认为间隔 65536 / n2个位有个值, 那么同时存在 n1和n2 的间隔为 t = ( 65536 / n1 ) * (65536 / n2),那么交集出来的个数为 m = 65536 / t = n1 * n2 / 65536 , 载拿 m 和 4096 进行比较 预判即可
2.数组和数组求交集 数据和数据求交集结果肯定还是用数组存
3.位图和数组求交集 位图和数组求交集也是用数组